AI Pachira Explore


AI Pahcira Trading Bot Platform
Section 1
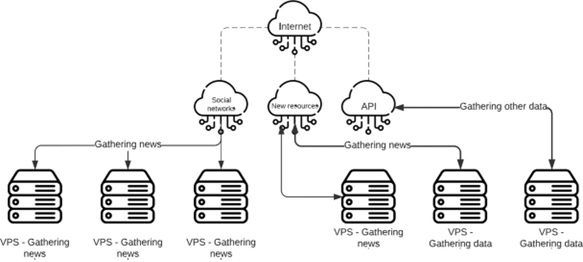
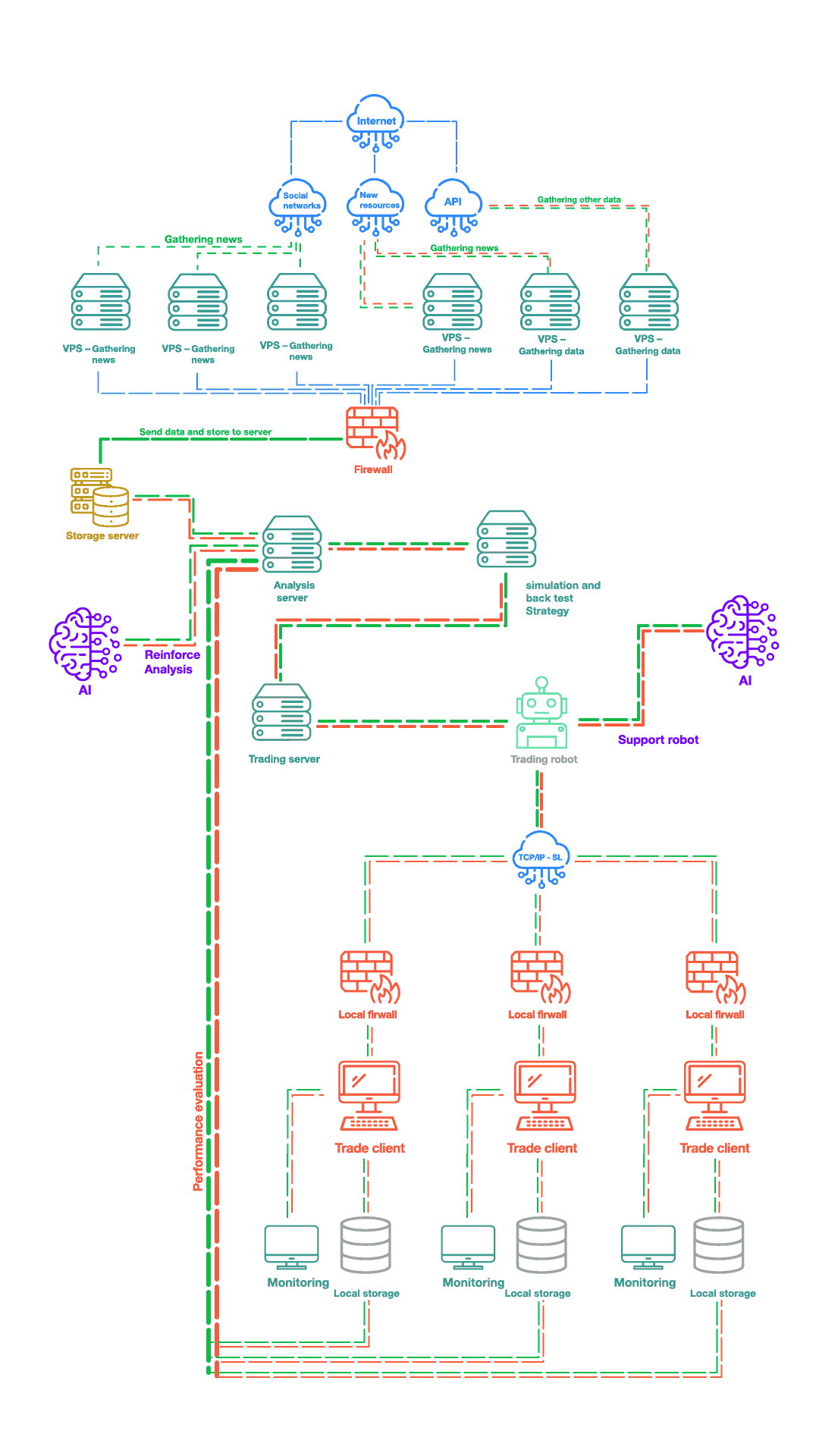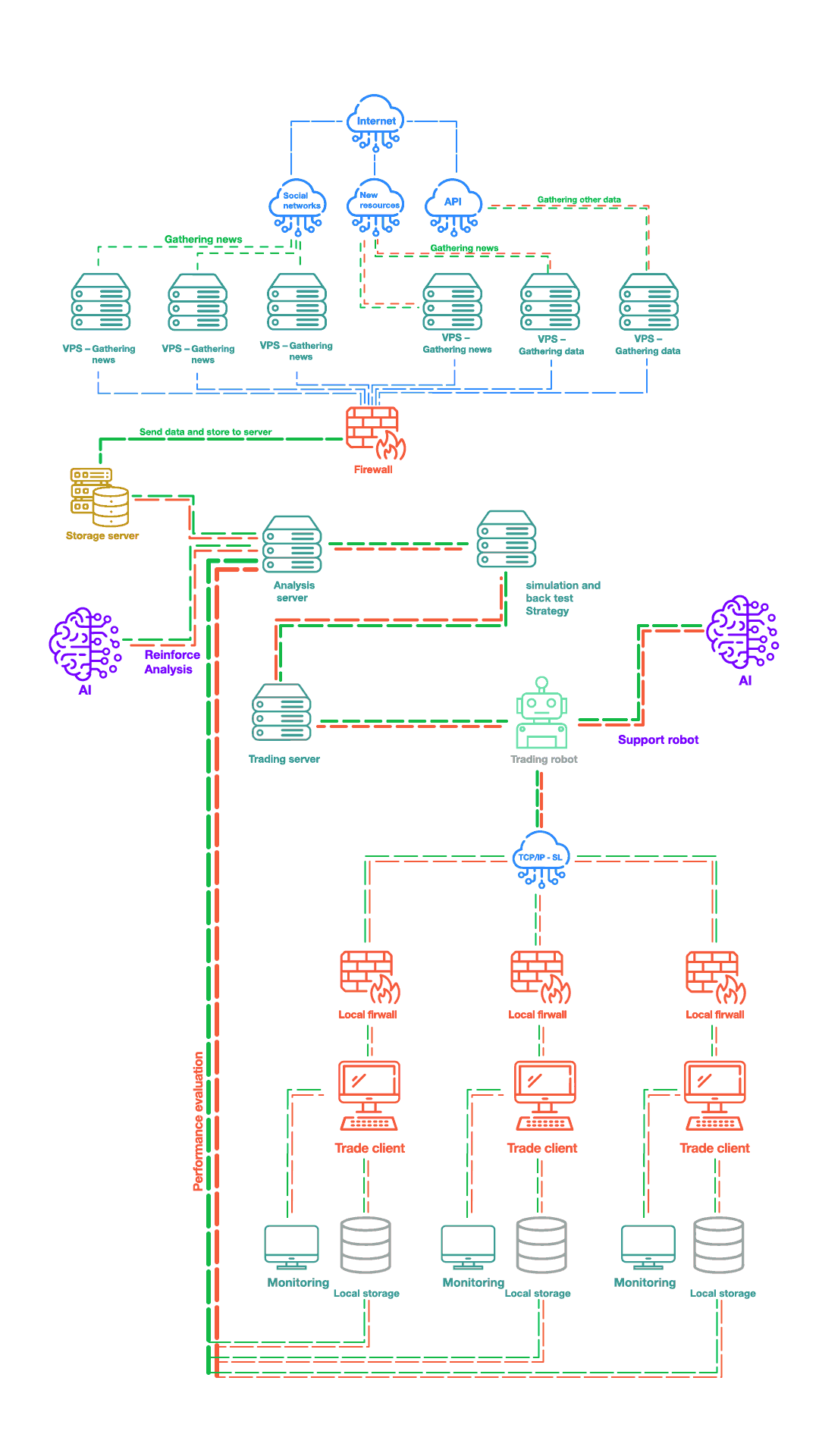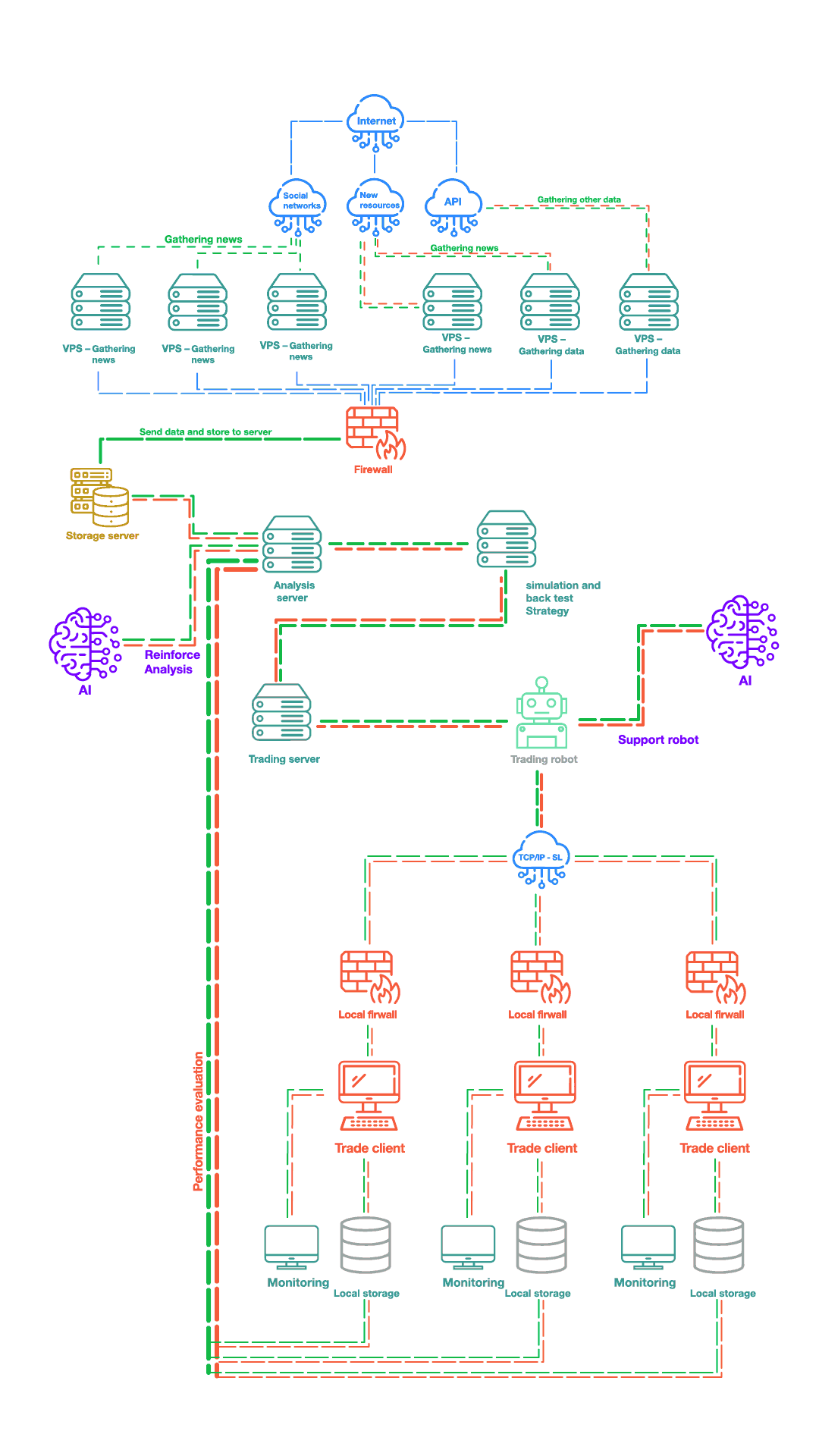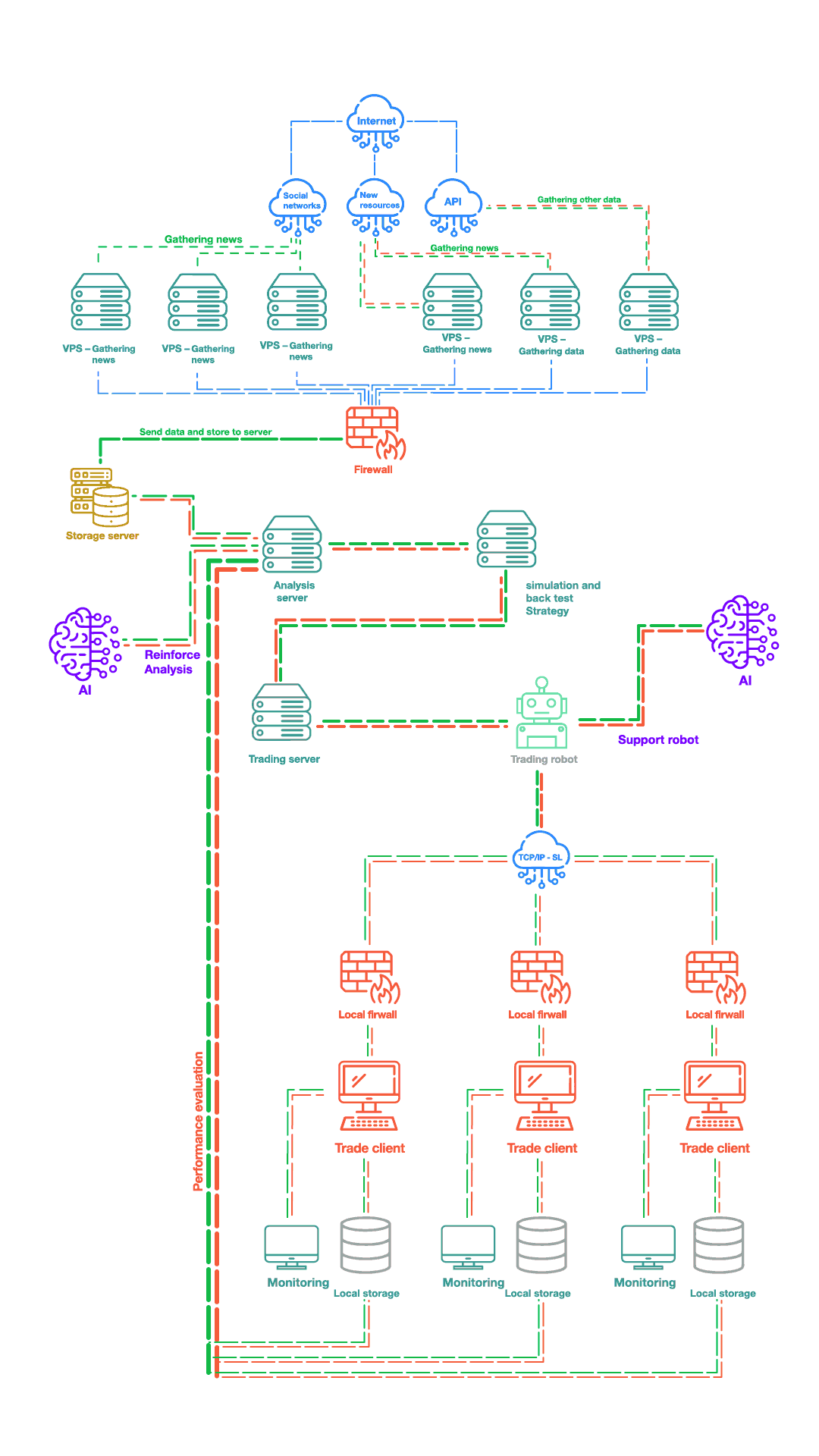
News Gathering and Analysis System
This system is designed for gathering news from official news sources, social media networks, and other sources that provide their services as API web services.
The gathering is performed using crawling bots across multiple VPS (Virtual Private Servers).
The crawling bots are implemented using programming languages such as Python, Go, and others.
The system utilizes automated news gathering systems to collect and analyze market and economic-related news, utilizing them for decision-making in trading. This system can provide us with real-time important information and, if necessary, identify significant events and make business decisions based on them.
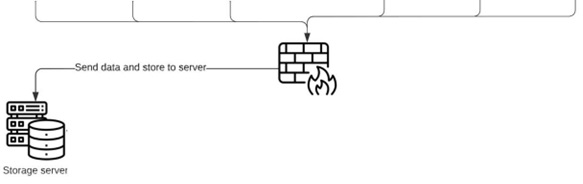
The collected data is stored in a dedicated store server after passing through hardware firewalls and using Big Data architecture.
Big Data Analysis
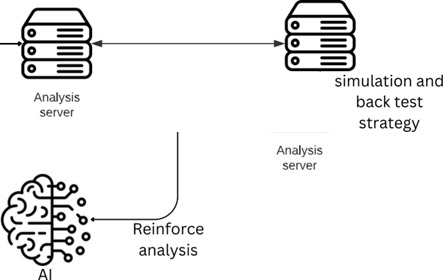
The collected data is fed into the analysis and processing server through multiple Kafka servers. The data is then processed using artificial intelligence algorithms to optimize the artificial intelligence model of the trading robot strategy.
Some of the key analyses in Big Data include:
To expedite and improve the analysis process, it is necessary to preprocess the data. This includes data cleaning, feature extraction, and dimensionality reduction.
Data cleaning involves removing any errors, inconsistencies, or outliers from the dataset. This ensures that the data is accurate and reliable for analysis.
Feature extraction involves identifying and selecting the most relevant features from the dataset that can contribute to the analysis. This step helps reduce the dimensionality of the data and focuses on the most informative attributes.
Dimensionality reduction techniques are applied to reduce the number of variables or features in the dataset without losing important information. This helps in simplifying the analysis process and improving computational efficiency.
Given the diversity and high volume of news articles, it is necessary to categorize them based on their topics and importance. This enables the separation of important and impactful news from less significant ones, allowing the system to focus on the more important news articles. News categorization involves assigning news articles to predefined categories or creating new categories based on the content and subject matter. This process can be automated using machine learning algorithms that learn from labeled data or through rule-based approaches. The categorized news articles can then be used for further analysis and decision-making.
To analyze and extract insights from the data, various artificial intelligence algorithms are employed, such as neural networks, machine learning algorithms, classification algorithms, and information extraction algorithms.
- Intelligent decision-making in the news gathering system involves leveraging precise analysis of various information and considering the dynamic conditions and factors in the decision-making process. This includes:
o Probabilistic analysis: Using probabilistic analysis, the likelihood of various events occurring is estimated based on news gathering information and market data. This helps in better evaluating risks and making more informed trading decisions. Probabilistic analysis involves applying statistical methods and models to assess the probabilities of different outcomes. It takes into account historical data, market trends, and news sentiment to calculate the likelihood of specific events, such as market fluctuations, price movements, or the success of a particular trade strategy.
o Predictive modeling: Predictive modeling techniques are used to forecast the trends and directions of price movements using news gathering data and market data. This involves utilizing statistical inference methods, neural networks, and machine learning algorithms. Predictive modeling leverages historical data, patterns, and correlations to build models that can make predictions about future price movements. It takes into account various factors such as market conditions, news sentiment, economic indicators, and technical analysis indicators.
o Decision-making algorithms: Decision-making algorithms such as decision trees, Bayesian methods, and Support Vector Machines (SVM) have been employed in the news gathering system. These algorithms, utilizing mathematical and statistical methods, enhance trading decisions based on news gathering information and market data. These decision-making algorithms use mathematical and statistical techniques to analyze news gathering data and market data, improving the trading decisions made within the system.
o Ongoing Performance Evaluation and Continuous Improvement: In the news gathering system, the system's performance is continuously evaluated, and necessary improvements are made based on market feedback and trading results. This includes updating models, improving decision-making algorithms, and more. The performance evaluation process involves monitoring the system's accuracy, efficiency, and effectiveness in capturing relevant news and making informed trading decisions. Key performance indicators (KPIs) such as profitability, risk-adjusted returns, and trade execution quality are assessed.
- Market analysis involves a detailed examination of market factors and conditions that are relevant to potential opportunities and risks, such as market maturity, order flow, order volume, and more. This analysis is essential for gaining a deeper understanding of market trends and trading dynamics.
After performing big data analysis on the collected data, several artificial intelligence models are created for conducting trades. These models include:
Utilizing artificial intelligence algorithms such as Neural Networks, Decision Trees, and Genetic Algorithms, along with reinforcement learning techniques, prediction model can be constructed using market price and volume data. These models aim to forecast prices, rate of change, and market trends. by analyzing historical data and learning patterns from the market, these prediction models can provide valuable insights into future market movements. They take into account various factors such as price fluctuations, trading volumes, and market indicators to generate forecasts. These models help traders make informed decisions, identify potential opportunities, and manage risks effectively. the use of artificial intelligence and machine learning techniques in building prediction models has revolutionized the field of trading, enabling traders to leverage data-driven insights and improve their trading strategies.
Employing statistical and probabilistic methods to estimate risk and assess the probability of trades. Techniques such as Regression Analysis and Cluster Analysis are utilized in this context
Regression models are used to identify and quantify the relationship between variables, such as market factors and trading outcomes. By analyzing historical data, regression models can provide insights into how changes in one variable affect others, helping traders assess risk and make informed decisions.
Cluster analysis is employed to group similar data points together based on certain characteristics or patterns. In the context of trading, cluster analysis can help identify market segments or clusters with similar behavior, allowing traders to assess the probability of certain outcomes or trends within each cluster.
Some of the parameters that are determined by the model for trading include:
• Learning rate: This parameter controls the step size at which the model updates its internal parameters during the training process. It affects the speed and stability of the learning process.
• Number of hidden layers: In neural networks, the number of hidden layers determines the complexity and capacity of the model to capture and represent underlying patterns in the data.
• Neuron activation functions: The choice of activation functions, such as sigmoid, ReLU, or tanh, determines how each neuron in the model processes and transmits information.
• Loss function: The loss function measures the discrepancy between the predicted output of the model and the actual target values. Different types of models may use different loss functions, such as mean squared error (MSE) for regression tasks or categorical cross-entropy for classification tasks.
• Trade entry and exit criteria: The model may define specific conditions or thresholds for entering and exiting trades. For example, it may consider factors such as price movements, technical indicators, or statistical patterns to determine when to initiate a trade and when to close it.
• Risk management parameters: The model may incorporate risk management techniques to control the size of positions and manage potential losses. Parameters such as stop-loss levels, position sizing rules, or risk-reward ratios may be considered to optimize the risk-return profile of the trades.
• Trade duration: The model may have parameters that define the expected duration of trades, such as short-term, medium-term, or long-term. These parameters can influence the frequency of trading and the holding period for positions.
• Market conditions: The model may include parameters that adapt its trading strategy based on market conditions. For example, it may have parameters to detect trending or ranging markets and adjust the trading approach accordingly.
• Trading volume or liquidity considerations: The model may take into account parameters related to trading volume or liquidity levels to ensure efficient execution of trades without significantly impacting market prices.
These parameters, along with the underlying algorithms and architectures of the models, play a crucial role in shaping the behavior and performance of the AI models in predicting market trends and making trading decisions.
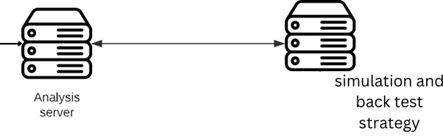
Based on the fact that multiple parameters may be suggested for each feature, the model is sent to a simulation server for backtesting with all the proposed parameters. This allows the model to be tested on historical data.
Simulation and Strategy Testing
After sending the model to the simulation server, the trading strategy generated by the model is tested on historical data. This process involves executing the strategy on past market conditions and evaluating its performance. The simulation server provides an environment that mimics real-time market conditions, allowing the model to make virtual trades and track its profitability.
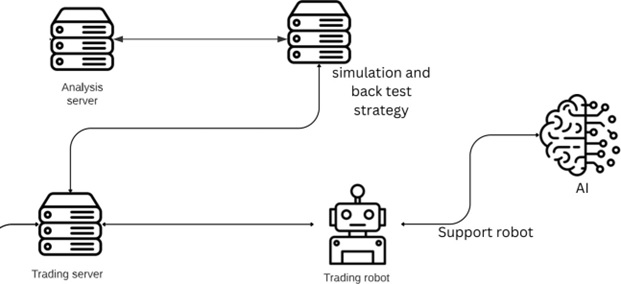
During the simulation and testing phase, various metrics and performance indicators are monitored, such as overall returns, risk-adjusted returns, maximum drawdown, win/loss ratio, and other relevant statistics. These metrics help assess the effectiveness and robustness of the trading strategy under different market scenarios.
The necessary parameters for the strategy are iteratively tested on historical data during backtesting. If the risk level and win rate are lower than desired, another parameter is substituted. This cycle is repeated for all potential parameters until the best parameters for the robot strategy are identified.
The Monte Carlo simulation method is used to analyze risk and exploit available opportunities. This method estimates the probability of events by repeating a large number of simulations and helps evaluate the performance of the strategy.
After experimenting with different parameters, the best parameters are selected, and the trading robot is optimized with the obtained model. The optimized trading robot is then sent to the trading server.

AI PACHIRA Robot Management Software
Section 2
The robot management software is implemented in a client-server architecture and includes the following entities.
• Analysis Server
• Trading Server
• Robot Management Software (Server)
• Robot Management Software (Client)
Analysis Server
This server is responsible for analyzing big data processing to support the selection of the best model for optimizing the trader robot. A detailed explanation of this was previously discussed.
Performance monitoring involves evaluating and monitoring the performance of the strategy after the completion of daily trades. This is done using indicators such as returns, profit/loss ratio, Sharpe ratio, and other relevant metrics.
After the clients activate their trading robots and store their transactional data in local memory, this data is sent to the analysis server for performance measurement and strategy monitoring./loss ratio, Sharpe ratio, and other relevant metrics.
Trading Server
• The execution of trades and trading activities performed by the robots is processed on the trade server.
• Performance monitoring: The server continuously monitors the performance of client robots, tracking key performance indicators such as profitability, risk metrics, and trading statistics. This enables performance evaluation and monitoring of the deployed strategies.
Robot Management Software (Server Side)
The execution of trades and trading activities performed by the robots is processed on the trade server.
Some of the features available in the robot management software on the server side include:
The server allows for the management and configuration of client accounts, including client registration, authentication, and access control.
The server stores and manages the trading data collected from clients, providing efficient storage and retrieval capabilities for historical data analysis and strategy optimization.
The server efficiently manages system resources, including CPU, memory, and network bandwidth, to ensure optimal performance and responsiveness for handling client requests.
The server facilitates the deployment of trading strategies to client robots, allowing for seamless integration and execution of the strategies in real-time trading environments
The server generates comprehensive reports and analytics on client performance, providing insights into trading activities, profitability, and risk analysis. These reports assist in decision-making and strategy refinement.
The server implements robust security measures to protect client data and ensure secure communication between clients and the server. Risk management features may include position limits, risk controls, and order validation mechanisms.
The server is designed to be scalable, allowing for the addition of new clients and accommodating increasing data volumes. It also incorporates high availability mechanisms to ensure uninterrupted operation and minimal downtime.
The server provides APIs that enable seamless integration with external systems, such as market data providers, trading platforms, and risk management tools, enhancing the functionality and flexibility of the robot management software
The server offers administrative tools and configuration options for managing system settings, user roles, permissions, and other operational aspects of the robot management software
Robot Management Software (Client Side)
In the client side, users can log into the software and define their MetaTrader accounts. They can activate and run their robots on each of their MetaTrader accounts.
Some of the features available in the client version of the software include:
- • Account configuration: Users can define their MetaTrader accounts.
- • Robot management: Users can activate and run their robots on their MetaTrader accounts.
- • Trade monitoring: Users can track their trades, view real-time data, and monitor market conditions on metatradee software.
- • Strategy customization: Users can adjust and customize trading strategies based on their preferences.
- • Performance analysis: Users can evaluate the performance of their trading activities and analyze trading results.
- • Risk management: Users can set risk parameters, including stop-loss and take- profit levels, to manage their trades.
- • Order management: Users can place, modify, and close orders directly from the client software.
- • Reporting and statements: Users can generate reports and statements to review their trading activities and performance.
- • Etc.
The software model is based on MVC. The Model-View-Controller (MVC) is a software design pattern that separates the data (Model), presentation (View), and control (Controller) components into distinct modules. This pattern aims to achieve better code management by separating the business logic, presentation, and control flow.
By separating the responsibilities of data management, presentation, and control, the MVC pattern promotes modular and maintainable code. It allows for easier code reuse, enhances testability, and supports the scalability of the application. Additionally, it enables multiple views to be associated with the same data, providing flexibility in presenting the information to users.
The communication between the client and server involves the use of the TCP/IP protocol and is encrypted for security purposes.
TCP/IP (Transmission Control Protocol/Internet Protocol) is a standard communication protocol suite used for connecting devices over the internet. It provides reliable and ordered delivery of data packets between the client and server. TCP ensures that the data is transmitted accurately and in the correct order, while IP handles the routing and addressing of the packets.
To enhance security, the data exchanged between the client and server is encrypted. Encryption is the process of converting the data into a coded form to prevent unauthorized access. Various encryption algorithms, such as AES (Advanced Encryption Standard), RSA (Rivest-Shamir-Adleman), or SSL/TLS (Secure Sockets Layer/Transport Layer Security), can be employed to secure the data during transmission.
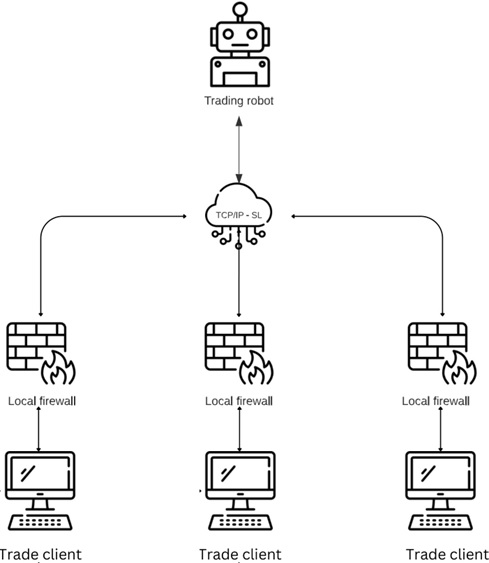
By using TCP/IP as the communication protocol and encryption techniques, the client and server can securely send and receive data, ensuring the confidentiality and integrity of the information exchanged between them.
In the client/server architecture, APIs (Application Programming Interfaces) are used as programming interfaces for communication between the client and server. APIs enable the client to send requests to the server and receive responses. They define the methods and protocols that clients can use to interact with the server and access its functionality.
By utilizing APIs, clients can make specific requests for data or perform certain actions on the server. The server processes these requests and provides the desired results or performs the requested actions. APIs serve as a bridge between the client and server, allowing them to communicate and exchange data seamlessly.
A database plays a crucial role in the client/server software architecture. On the server side, the required data for client applications is stored in a database. The database serves as a centralized repository for storing and managing structured information.
The database enables clients to perform various operations on the data, such as managing, searching, and updating. Clients can send requests to the server to retrieve specific data, modify existing data, or add new data to the database. The server processes these requests and interacts with the database accordingly, returning the requested results or confirming the data modifications.
In this software, both relational SQL and non-relational (NoSQL) databases are used.
Client data is stored in a local database and then sent to the analysis server for performance evaluation and strategy monitoring.
In the client-server architecture, the client application is responsible for managing and storing its own data locally. This data can include various information such as user profiles, transaction history, preferences, and any other relevant data specific to the client's activities.
The local database on the client side provides a convenient and efficient way to store and retrieve data without the need for constant communication with the server. This allows for faster access to data and better responsiveness of the client application.
Security
In client-server architecture, security is a vital aspect. It includes security in communications (encryption), user authentication (e.g., through usernames and passwords), access control management (to determine what information is accessible to each user), and error and exception handling.
Ensuring secure communication between the client and server is crucial to protect sensitive data from unauthorized access or interception. Encryption techniques, such as SSL/TLS protocols, can be employed to encrypt data during transmission, providing confidentiality and integrity./loss ratio, Sharpe ratio, and other relevant metrics.
User authentication is essential to verify the identity of clients and prevent unauthorized access. This typically involves the use of usernames and passwords, where clients provide their credentials, and the server verifies them before granting access to the requested resources. Additional security measures, such as multi-factor authentication, can be implemented to enhance user authentication.
Access control management involves defining and enforcing different levels of access for users. This ensures that each user has access only to the appropriate information and functionalities based on their roles and permissions. Role-based access control (RBAC) or attribute-based access control (ABAC) mechanisms can be employed to manage and enforce access policies effectively.
Error and exception handling is crucial for managing and mitigating security risks. Proper error handling and exception management help identify and respond to potential security vulnerabilities, such as input validation errors, authentication failures, or access violations. It allows for graceful error handling, logging, and reporting, ensuring the stability and security of the system.
Logging and auditing are essential processes in client-server architecture. They involve recording events, activities, and incidents within the system. These logs can be used for tracking and investigating security-related issues and assist in the detection and response to attacks.
Intrusion prevention refers to a set of security measures aimed at preventing unauthorized access and attacks. The objective of intrusion prevention is to detect and block intrusion attempts, thereby safeguarding the client-server system from potential threats. These measures may include the use of firewalls, intrusion detection systems (IDS), and threat detection mechanisms.
Incident recovery is a phase of system security that focuses on restoring the system to its normal state and recovering from the damages caused by a security incident or attack. The primary goal of incident recovery is to minimize the impact of the incident, restore the system's functionality, and improve its security posture.
In order to store and transmit sensitive and important data securely, a combination of encryption algorithms and secure protocols is used. Encryption is the process of converting plaintext data into ciphertext, making it unreadable to unauthorized individuals. This ensures the confidentiality and integrity of the data:
- • There are various encryption algorithms available, such as AES (Advanced Encryption Standard), RSA (Rivest-Shamir-Adleman), and HMAC (Hash-based Message Authentication Code), among others. These algorithms use mathematical operations and keys to encrypt and decrypt data.
- • End-to-End Encryption (E2EE) is a method where data is encrypted at the source and remains encrypted throughout its transmission until it reaches the intended destination. In this approach, only the source and the destination have the ability to decrypt the data, meaning that no intermediate servers or potential eavesdroppers along the communication path can access the encrypted data.
- • Key Management: For encryption and decryption of data, you need to use a strong encryption key. Public-Key Cryptography, also known as asymmetric encryption, is a common and popular method in the field of information security. In this method, we have two different keys with a relationship: the public key and the private key. By using public-key encryption, it is possible to send information in an encrypted form that can only be decrypted using the corresponding private key. Thus, if the information is intercepted during transmission, its content cannot be understood.
User Authentication in the software:
- • Username and password
- • Second factor authentication (sending a one-time code to email or mobile)
- • Google Authenticator
- • Hardware token authentication dedicated to each user
- • Biometric authentication using facial recognition technology
Implementation and deployment time of software:
The implementation and deployment time of software refer to the duration required for its development and launch. This time includes the processes of software development, design, coding, testing, server configuration, and ultimately deploying and launching the software on the desired servers or systems.
Our suggested timeframe for designing and deploying this software is between 30 to 45 days.
AI Pachira Block Diagram